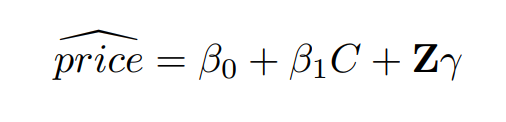I am currently pursuing a Masters in Data Science at UC Berkeley. I will be graduating May 2024.
While pursuing my masters, I am working part time as a Data Scientist at Enact MI.
As a Data Scientist, I have worked on developing multiple models for differnet business use cases.
These use cases are; analyzing the attributes that contribute to new loan delinquents, developing a method to understand the NIW market size at a monthly level, and improving our LLM use case capabilties.
In my final semester, I am working with a team to devleop an app to interpret American Music Lyrics using Gen AI.
My prior completed courses are: Introduction to Data Science Programming, Research Design and Applications, Probability and Statistics, Introduction to Data Engineering, Applied Machine Learning, Machine Learning Systems Engineering, Experiment and Causal Inferences (AB Testing Focused), and NLP & LLM Modeling.
I have gained a certification from completing a Python Bootcamp, SQL Mastery course, and an Introduction to Analytics 2 course provided by NC State.
If you would like to contact me please reach out via email (celee@berkeley.edu).
Projects
Below are buttons that links to different projects I have worked on.
Each project goes into depth of the different analysis I or a team I collaborated with conducted.
Please check out any that interest you. Stay tuned I will be adding more projects
About Me
Christian Lee (He/Him)
I am pursing a Master's in Data Science at UC Berkeley to further build my skill set as a Data Scientist.
While pursuing my masters, I am working part time as a Data Scientist at Enact MI.
As a Data Scientist, I have worked on developing multiple models for differnet business use cases.
These use cases are; analyzing the attributes that contribute to new loan delinquents, developing a method to understand the NIW market size at a monthly level, and improving our LLM use case capabilties.
Prior to becoming a full time student I was working as a Senior Analyst at CREO working on a plethora of different projects.
At the consulting firm I help developed 30+ process maps to identify bottlenecks, pain points, and areas to invest in to drive operational improvements.
Worked with SMEs to assess data governance practices, analytic platforms, data strategy, and data pipelines for cliental.
Prior to switching to the data world, I majored in Chemical Engineering at NC State.
I worked as a process/project engineer and ended my career as a project manager.
I have a lot of experience with good documentation practices, developing and executing engineering studies, and commissioning and qualification of new equipment.
Check out my Linkedin page for more work related information.
Introduction
You have been hired by a major retailer to develop algorithms for an online ad auction. Your client knows a little about the multi-armed bandit literature and recognizes that it can spend money to explore, learning how likely users are to click on ads, or to exploit, spending on the most promising users to maximize immediate payoffs. At the same time, there are other companies participating in the auction that may outbid your client, potentially interfering with these goals. Your task is to model the ad auction and develop an effective algorithm for bidding in a landscape of strategic competitors. Your client plans to test your bidding algorithm against other bidding algorithms contributed by other data scientists, in order to select the most promising algorithm.
The Auction Rules
The Auction has a set of bidders and users and multiple rounds representing an event which a user navigates to a website with a space for an ad. When this occurs the group of bidders will place to have an opportunity to show the select user their ad. The user may click or not click the ad and the winning bidder gets to observe the users behavior. The rule is the same as a second price sealed-bid auction.
There are num_users User s, numbered from 0 to num_users - 1 . The number corresponding to a user will be called its user_id . Each user has a secret probability of clicking, whenever it is shown an ad. The probability is the same, no matter which Bidder gets to show the ad, and the probability never changes. The events of clicking on each ad are mutually independent. When a user is created, the secret probability is drawn from a uniform distribution from 0 to 1.
There is a set of Bidder s. Each Bidder begins with a balance of 0 dollars. The objective is to finish the game with as high a balance as possible. At some points during the game, the Bidder 's balance may become negative, and there is no penalty when this occurs.
The Auction occurs in rounds, and the total number of rounds is num_rounds. In each round, a second-price auction is conducted for a randomly chosen User. Each round proceeds as follows:
1. A User is chosen at random, with all User s having the same probability of being chosen. Note that a User may be chosen during more than one round.
2. Each Bidder is told the user_id of the chosen User and gets to make a bid. The bid can be any non-negative amount of money in dollars. A Bidder does not get to know how much any other Bidder has bid.
3. The winner of the auction is the Bidder with the highest bid. In the event that more than one Bidder ties for the highest bid, one of the highest Bidder’s is selected at random, each with equal probability.
4. The winning price is the second-highest bid, meaning the maximum bid, after the winner's bid is removed, from the set of all bids. If the maximum bid was submitted by more than one bidder then the second price will be the maximum bid. For example, if two bidders bid 2 and no one else bids higher then 2 is the winning price.
5. The User is shown an ad and clicks or doesn't click according to its secret probability.
6. Each Bidder is notified about whether they won the round or not, and what the winning price is. Additionally, the winning Bidder (but no other Bidder) is notified about whether the User clicked.
7. The balance of the winning Bidder is increased by 1 dollar if the User clicked (0 dollars if the user did not click). It is also decreased by the winning price (whether or not the User clicked).
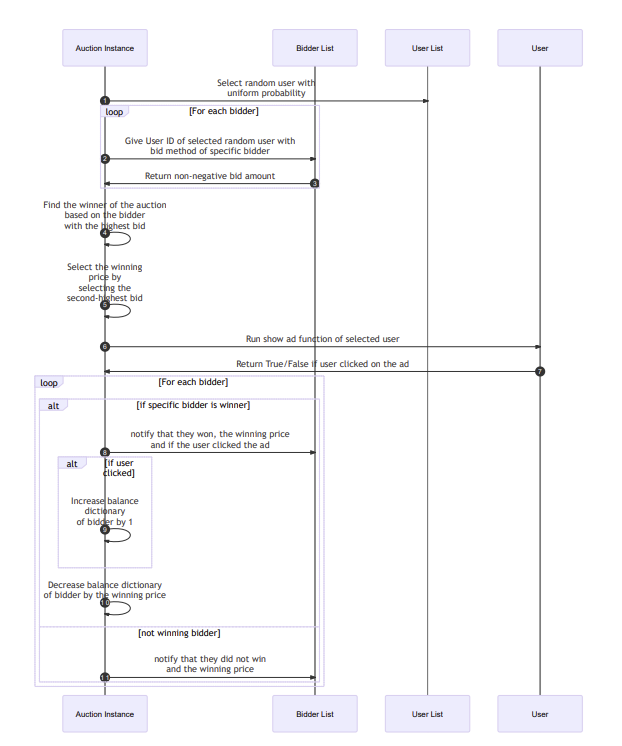
Sequence Diagram
Game Setup
1. Create Users.
2. Create Bidders.
3. Designate number of rounds.
4. Create Auction object with user and bidder list passed in.
Running the simulation
5. Auction class will be called and will randomly choose a user.
6. The auction asks if the bidders would like to bid for a specific user.
7. Bidders have the option to bid knowing who the user is.
8. The highest bidder is selected but only gets charged the second highest bid amount. If a tie occurs, then a bidder is randomly chosen out of the two and the tied bid will be the charged bid cost.
9. The ad is shown to the user and the user will randomly choose to watch the ad. Each user has a different probability whether to watch or not.
10. The user sends information to the auction whether the ad was watched, and the auction notifies the winning bidder if the user watches or not.
11. If the user watched, then the bidder is rewarded a dollar.
12. The auction holds the balance of each bidder and updates the accounting books (a dictionary object).
13. Another round will be played until the auction has reached the set number of rounds played.
Deep Dive into the Architecture and Code Architecture for each user:
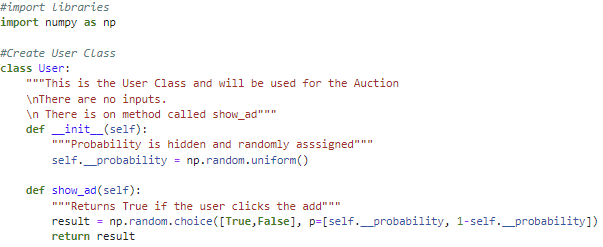
The code below is the user class. Each user object has a random probability designated. The show_ad function in the user class is binary choice to watch or not watch the ad and will return the results to the Auction. The show_ad function is called in the auction class.
Architecture for the bidders:
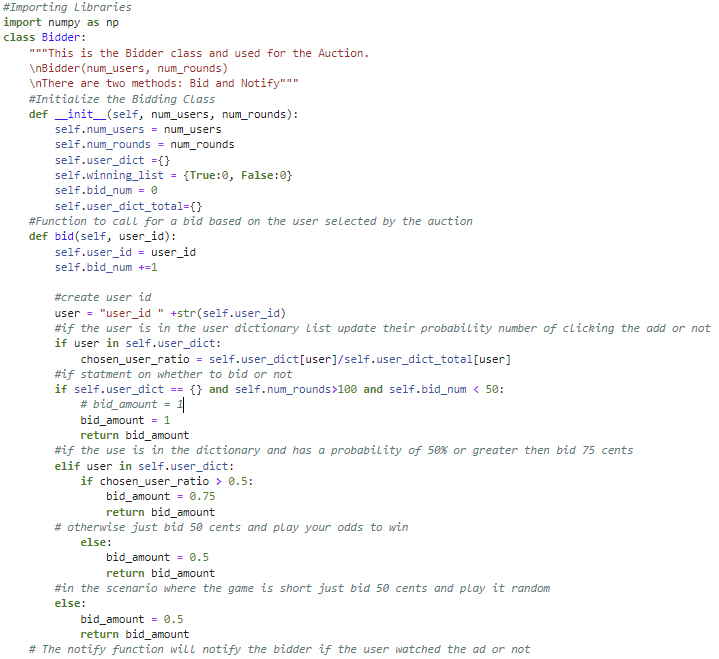
In this section I will go through the architecture of the bidder class at a high level. There are comments in the code to explain each portion of the code.
The class Bidder can pass in two parameters, the number of users in the auction and the number of rounds the auction will conduct. Each bidder object will have an idea of the number of users, number of rounds, a dictionary of the users (key is the users and values are the number of times the bidder has won a bid for that user), a personal winnings list, a counter to count the number of bids made, and user dictionary to see how many times a user has watched an ad. The bid function will be called during the auction class. The bid can take in the user parameter. The idea for this code is collect information of the user and make a strategic bid. The way I designed this algorithm is to find that user from the bidders users list and take the ratio of times the user has watched over the times the bidder has paid to show the user an ad. For the first hundred rounds the bidder bids a dollar, not exceeding the winnings cost, to collect information and stop other bidders from knowing the users. By taking each users information early on, I am able to learn about the user and learn the probability of the user clicking the ad or not. Having this information early on I can bid aggressive for the users with high probability. The code has room for improvement to better designate the probability requirement for how willing a bidder will pay. Under the stringent time frame when the code was developed, this was gauged with a couple of simulations. If time was allowed, I would have run over a hundred simulations of the different bidder models and run a regression on probability amount and bis amount to find the highest return.
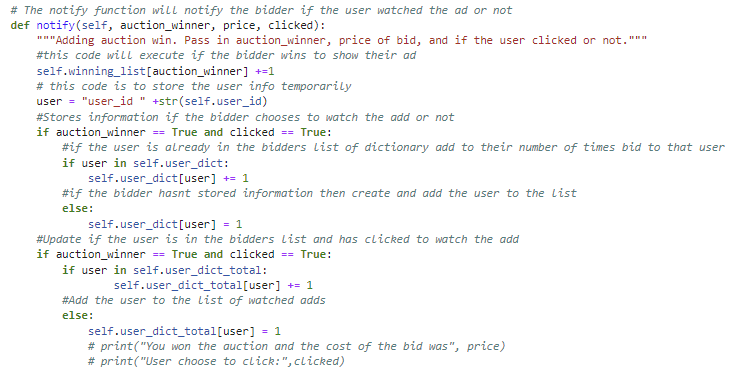
The notify function within the bidder’s class is to notify the bidder if the user has watched the ad or not. This function is executed in the auction class. This portion of the code is where the bidder collects information on the user’s activity and learns more about the users actions.
Please note that one bidder was created and tested and competed with other bidder classes created by other students. There was a competition within the programming class to see whose bidder would have the highest return. My bidder and the bidding strategy was in the 90th percentile.
Architecture for the Auction:
The Auction class takes in the users list and bidders list. The auction creates a dictionary of the bidders and stores information on the bidders’ balance.
The two code snippets below are both snippets of the execute_round function. The execute_round function within the Auction class is to simulate an event/round of the auctioning. First a user is randomly selected, and the bidders’ bid function is called for each bidder. The bidders are told which user was chosen to potentially click their ad and the bid function is called to see whether a bidder wants to bid on that viewer. Afterwards the auction finds the highest bidder by using the max function to parse through the bidders list. Now the auction object needs to find the second highest bidder and that is done by sorting through the bidder dictionary values and choosing the second highest. Then the auction checks to see if the first highest bidder had bid more than the second highest bidder. If the bids are not equal, then the winner is the highest bidder, and the highest bidders pays the cost that is equivalent to the second highest bidders bid. If bids are equal than the bidder is randomly chosen from the two. After the highest bidder has paid the second highest bid price, the user is shown the ad and decides to click it or not. If the ad has been viewed than the balance of the highest bidder has increased by 1 dollar. The other bidders are notified that the bidder has won the bid but not if the viewer has clicked the ad or not. The highest bidder is notified if the viewer had clicked the ad or not.
Running the code
If you would like to run my code you can open the Test_py_files.ipynb jupytr notebook and run the code seen below. At the top of the page is my github folder for the program and where you can access the code. You will need to have the numpy library in order to run the code. The numpy library was used for the “random” functions.
Overview Climate change can negatively impact the world by producing severe droughts, rise in sea levels, and extreme weather conditions resulting in natural disasters on a scale never seen before. Climate change is the accumulation of greenhouse gasses resulting in long-term change in global temperature and weather patterns. There are many natural reasons for greenhouse gasses to be emitted, but a significant portion of emissions are generated by humans. Greenhouse gasses are comprised of 7 types of gasses and the greenhouse gas that is largely generated due to the human factor* is Carbon Dioxide (CO2).
In this project we will be exploring multiple aspects and uncovering insights with CO2 emission with population growth and income groups, countries energy production and consumption, and clean energy production.
By exploring the datasets of CO2 levels, we intend to discover: 1. What is the direct impact of population growth w/o accounting for energy type to CO2?
2. What trends are we seeing in the adoption of different energy types across countries? Are these trends different based on the country's income group - low, medium, high?
a. How does the energy trend look in the world regions?
b. What is the trend for the death rate per 100K population based on air pollution, and is there any relationship to CO2 emission?
3. What is the world’s trend on renewable energy production?
4. Which large country had the greatest percent decrease in CO2 emissions from their peak?
Data Preperation
When we initially started this project, we tried to find a main dataset that was already in good condition. There were several other topics we thought of doing but their datasets were far too messy. Because of this, there wasn’t too much that we needed to do to get our data ready for analyzing. Most of our files came in completely fine but there was one (Supplemental Dataset 1) that had 4 extra rows on the top for the title and date. Python would get an error when trying to import the data, so we had to manually delete the top 4 rows.
After this we were able to import all the datasets with no problem. Once we stored the data as dataframes the next step was to get rid of any columns that didn’t have any information a.k.a. NaN values. We did this to all four of our dataframes and moved on to renaming the columns to something that was easier to use. We renamed any similar columns to have the exact same name, for example “Country Name” would be renamed to “Country” because it’s shorter, easier to work with (spaces make referring to a column difficult), and it made all the datasets match. Next, we needed to make all the dataframes have only 1 year column. Supplemental Dataset 1 had columns for every year, so we melted that dataframe to match the others.
We needed to be able to work with the numeric values of our data, so we converted all numeric values into numeric types. This way we could use aggregation functions on them like sum(), max(), and mean(). After this we wanted to combine several of our dataframes together to create one big final dataframe that we could all use to start with. In order to do this, Supplemental Dataframe 2 needed to have a column of “Energy_type” with the value of “all_energy_types”. Then we merged Supplemental Dataframe 2 with Supplemental Dataframe 1 to create a combined supplemental dataframe. Finally, we merged our Main Dataframe with the combined supplemental dataframe and created the final dataframe. In the end, our final dataframe contains 55,440 rows and 14 columns. It has information from 1980 to 2019 and contains information on 230 countries.
Supplemental Dataframe 3 was added so we could ask even more questions about the impact of CO2 on deaths. We decided to create another version of the final dataframe because we already had invested a lot of time into the project and didn’t want to change the original final dataframe. We also added Supplemental Dataframe 4 that included all the countries and their country codes because the main dataset didn’t include every country. This dataframe was added to create a time series choropleth map.
What is the direct impact of population growth w/o accounting for energy type to CO2? We have observed no direct relationship between population growth experienced by a country and its CO2 emission levels. It is observed that industrialized nations tend to produce higher levels of CO2 compared to countries with similar population growth but much less industrialization and manufacturing capabilities.
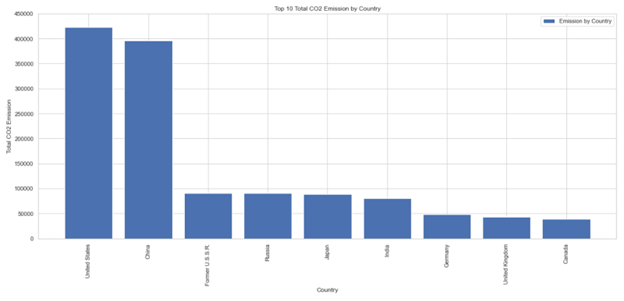
Figure 1: Top 10 countries with highest total CO2 emissions
Figure 1 showing the total C02 emission by top 10 countries. At the start of the research, we were assuming China, and India to be the top two producers. Our analysis showed that the USA has emitted the highest total CO2 for the period recorded in this study (1980 – 2019) closely followed by China.
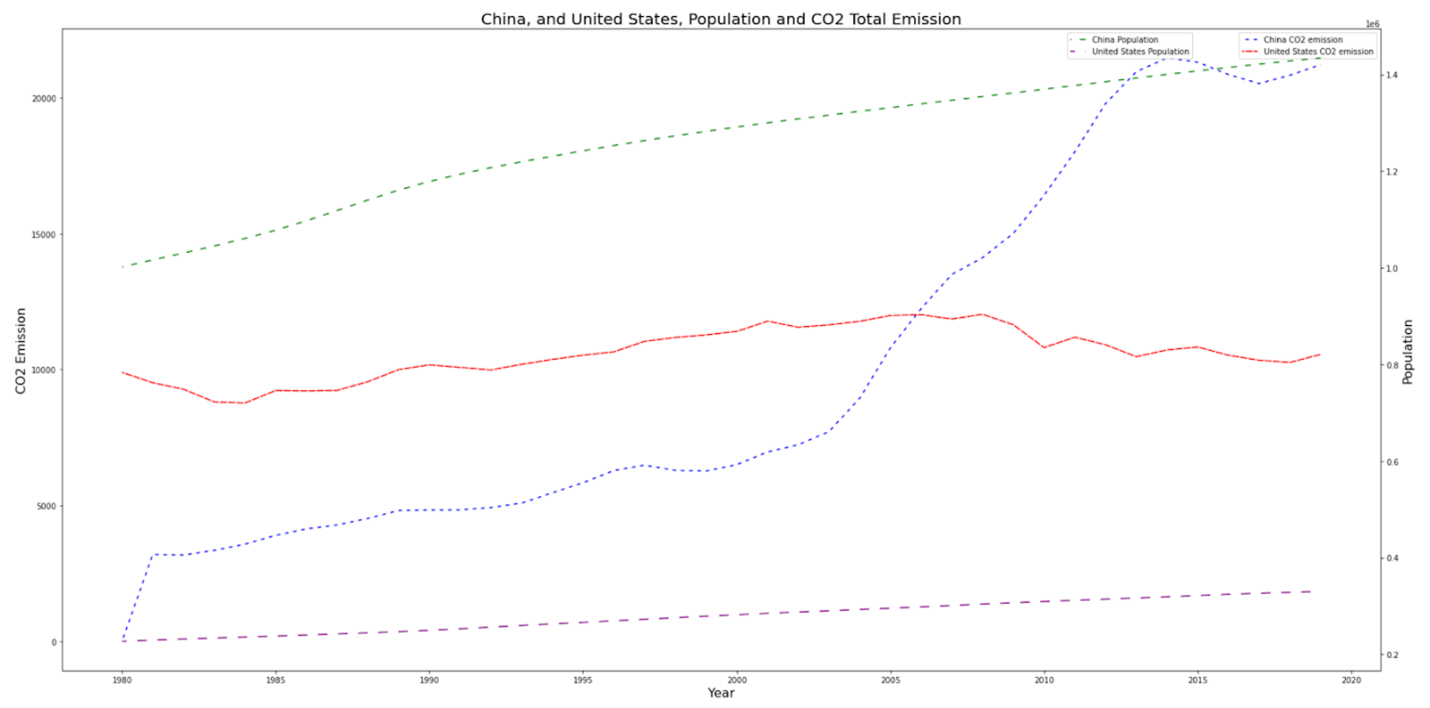
Figure 2: CO2 emission, and population growth trend for USA, and China
Figure 2 above shows detailed CO2 emissions by China, and the US over the research period. Both countries show a growth in population trend, the US over the last decade has made efforts to reduce the CO2 emission, although more recently it has started trending upwards again. China made some effort to reduce CO2 emission in the last decade as well but is trending upward again and is the top CO2 emitter for the current decade.
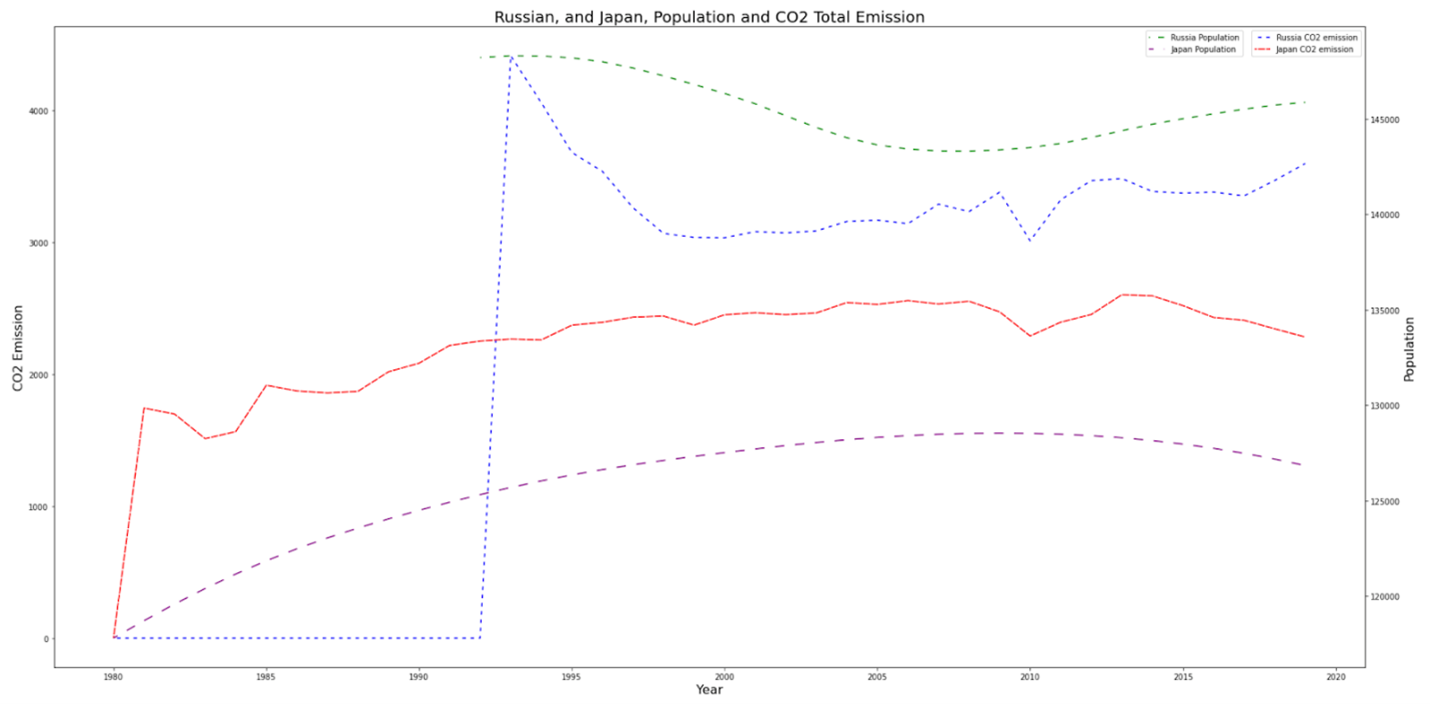
Figure 3: CO2 emission, and population growth trend for Russia, and Japan
Figure 3 demonstrates another view to illustrate that although both Japan, and Russia experienced a downward trend in population growth, the CO2 emission didn’t follow the same trend.
What trends are we seeing in the adoption of different energy types across countries? Are these trends different based on the country's income group - low, medium, high?
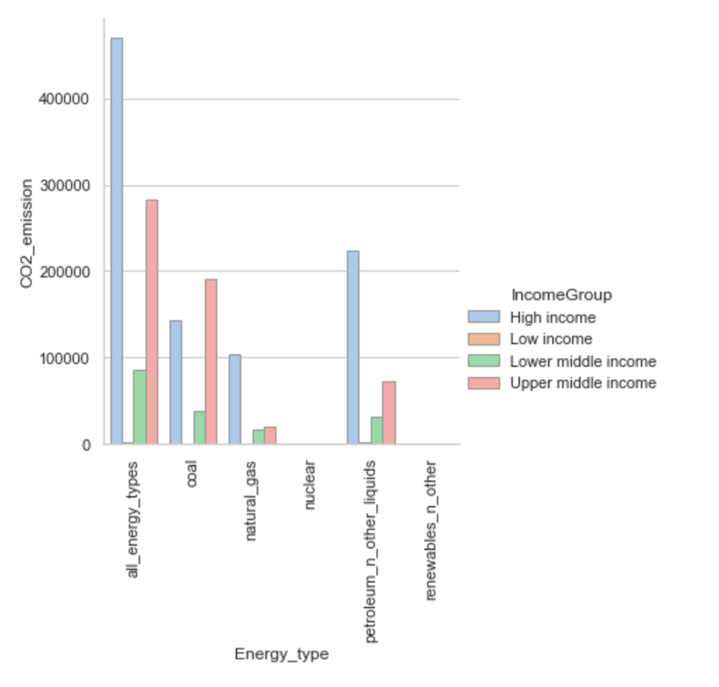
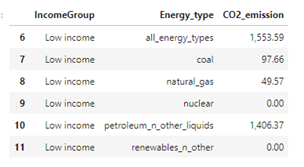
Figure 4: CO2 emission by energy type and income groupTable 1: Listing the low CO2 emission for low income countries
Note for the data above nuclear and renewables_n_other have no direct CO2 emission and are listed as Zero. Following observations can be made from Figure 4, and Table 1 about the question of adoption of different energy types across countries based on different income group:
• Low-income countries' contribution to the overall C02 emission is the lowest.
• Low-income countries primarily rely on petroleum-based energy types.
• CO2 emission is directly related to the GDP of the income group, higher income group countries are responsible for higher CO2 emission rates.
• Coal based energy type is the highest contributor for Upper middle-income countries
• Petroleum based energy type is the highest contributor for High income countries
• For both Lower middle income, and Upper middle income countries CO2 emission based on natural gas is similar.
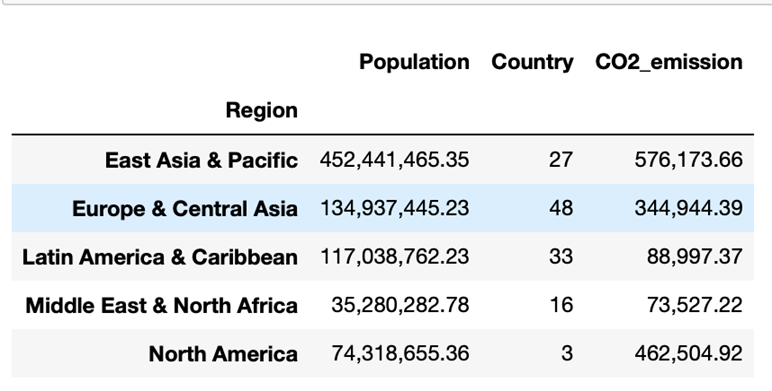
How does the energy trend look in world regions? Note on the dataset – the dataset and the supplement dataset used does not categorize all world countries by ‘Region’ designation, therefore the data analysis and visualization for this sub-question represent a trend of 130 countries as shown in the Table 2.
Table 2: Population, Number of countries, and CO2 emission by region
It is noticeable that both Former U.S.S.R. and Russia did not have the ‘Region’ designation and are not included in the trend report. The North American region contains the United States, and Canada.
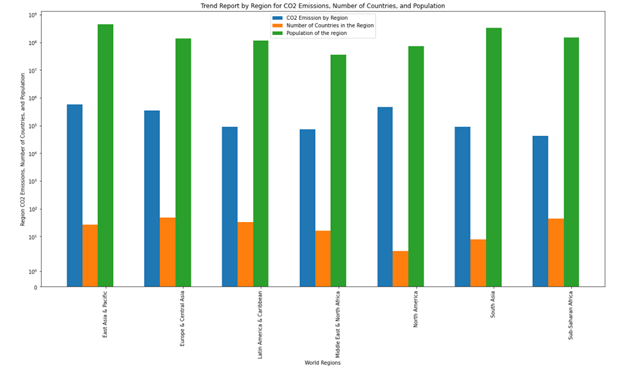
From Table 2 the clear trend is that most of the CO2 emission currently is happening from the East Asia and Pacific region that includes China which is the global manufacturing hub.
In the future if additional data becomes available for the past three years (2020-2022) that’ll be an interesting observation for the impact of the sars-cov-2 pandemic and how various global and regional shutdowns impacted the CO2 emission rates.
Figure 5: Trend report by region for CO2 emissions, number of countries, and population
Figure 5 shows the CO2 emissions by region and total number of countries, and population contributing to the trend. Table 2 dataset is used to build out Figure 5.
What is the trend for the death rate per 100K population based on air pollution?
Figure 5 shows the CO2 emissions by region and total number of countries, and population contributing to the trend. Table 2 dataset is used to build out Figure 5.
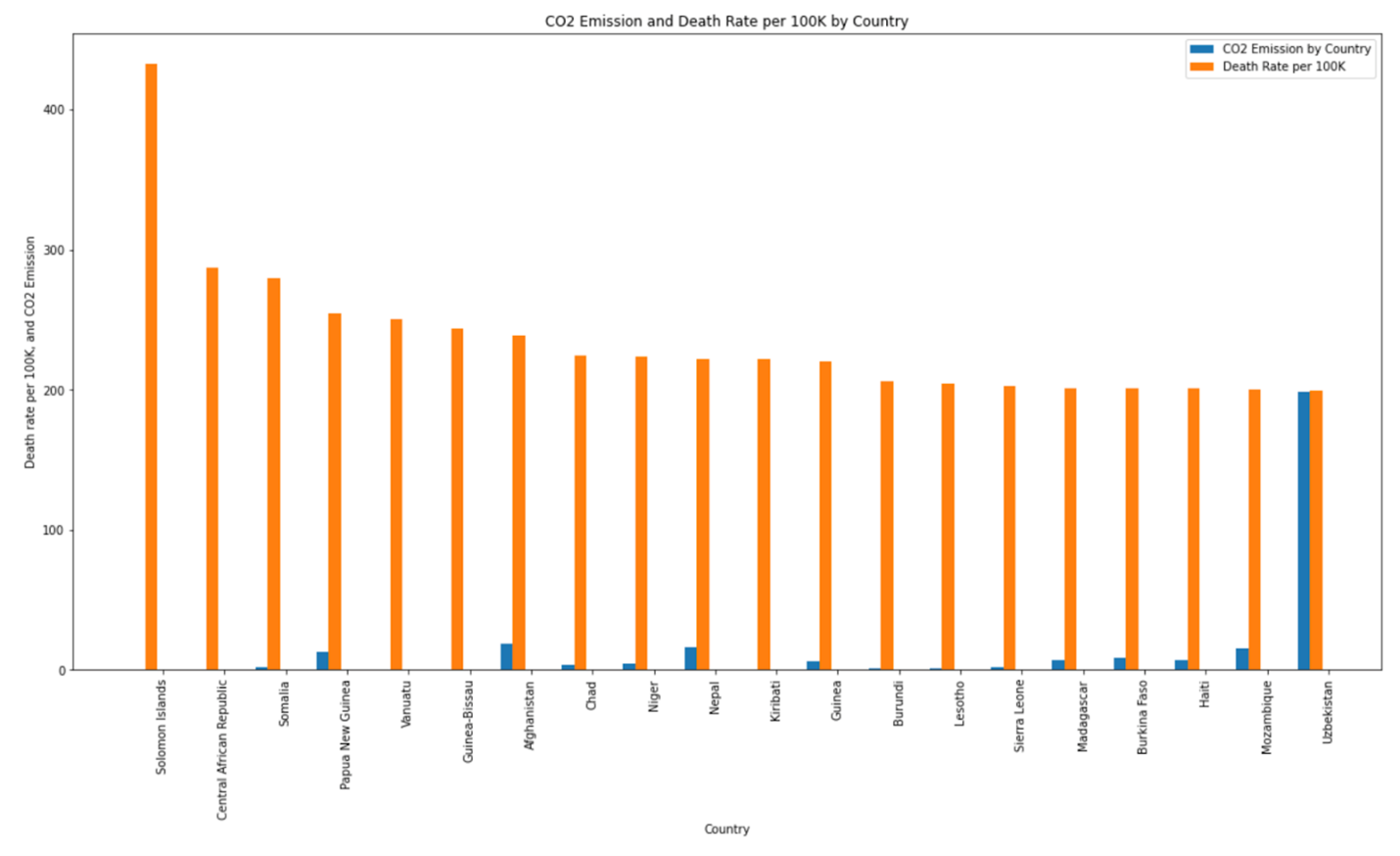
Note: There is a detailed heat map showing the trend in the death rate for each country in the jupyter notebook, for the sake of brevity, only top 20 countries with the highest death rate for the year 2019 are included in this report, Figure 6 below shows that using bar plot.
We did additional analysis on the death rate per 100K based on air pollution and noticed that the CO2 emission for Solomon Islands is one of the lowest on record. In order to ensure that the death rate per 100K was in fact this high for Solomon Islands we did literature research (Health Impacts of Climate Change in the Solomon Islands: An Assessment and Adaptation Action Plan: Jeffery T Spickett, and Dianne Katscherian 2014 Jun 24.) and uncovered that the death rate due to air pollution in Solomon Islands is a concern and health intervention is needed to increase understanding of the possible links between climate change, air quality, and health.
Figure 6: Top 20 countries by death rate per 100K due to air pollution, and corresponding CO2 emission for the year 2019
In conclusion we observe no relationship between the CO2 emission and death rate per 100K based on air pollution as plotted in Figure 6.
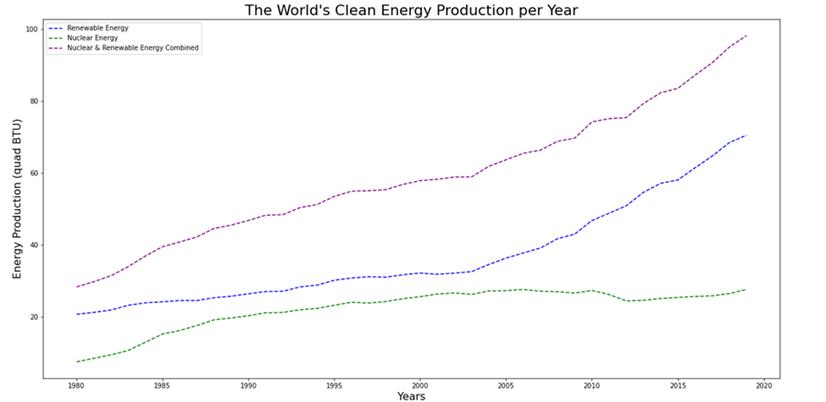
What is the world’s trend on renewable energy? We were interested to see if the world is taking climate change seriously and how has the world responded to the topic by generating renewable energy. By creating three different data frames we can plot, seen in Figure 7, the energy trend for renewable energy, nuclear energy, and the combination nuclear and renewable energy production per year.
Figure 7: The world’s clean energy production is increasing every year.
The renewable energy production has slowly increased until 2003 where it has increased at a higher rate than ever seen before. Nuclear energy had a large increase in the 1980 to 1985 and stopped increasing as much when renewable energy started to pick up. From 2004 to 2019 there has been a rise of renewable energy and a decrease in nuclear energy. The overall trend for the world is an increase in renewable energy and nuclear energy. We have defined clean energy as the summation of nuclear and renewable energy.
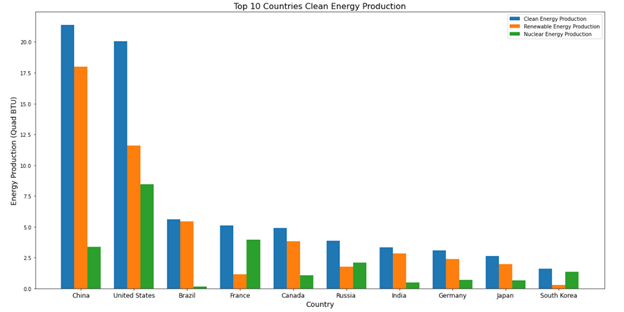
Figure 8: China produces the most clean energy.
The top 10 countries producing clean energy can be seen in Figure 8. China has produced the most renewable energy in 2019 while the US produces the most Nuclear Energy in 2019. Overall, China produces the most clean energy. The countries in Figure 8 are countries that are in the top 15 highest GDP rankings based on Investopedia[1].
Which large country had the greatest percent decrease in CO2 emissions from their peak?
The first step was finding out when a country peaked in CO2 emissions. Once we found out which year was each country’s peak, we looked at any time after that for the lowest CO2 emission year. Then we subtracted the low from the peak to find the total decrease in CO2 emissions. We turned that into a percentage to find out which country had the largest percentage drop from their peak. The results weren’t very informative.
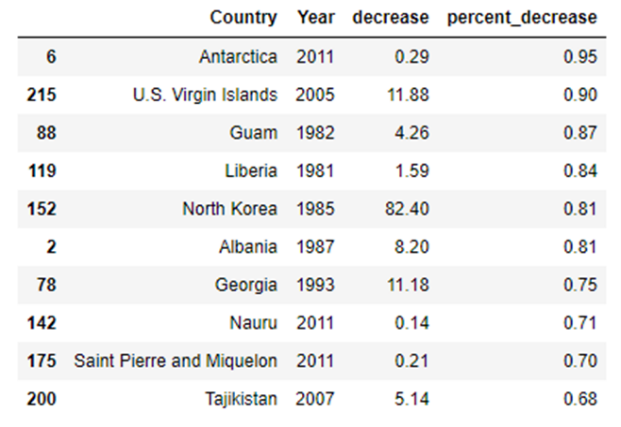
Table 4: Largest percent decrease of all countries
As you can see, our top country was Antarctica and then the U.S. Virgin Islands. Those countries are so small that any small change could cause huge swings in their CO2 levels. This made us update our question to include “large country” and “percent decrease” to avoid ambiguity of what we meant by the word decrease. So, we decided to look at the top 10 countries with the highest total drop in CO2 levels and then sort those by who had the highest percentage drop in CO2 levels. When we did that, we got a much better list.
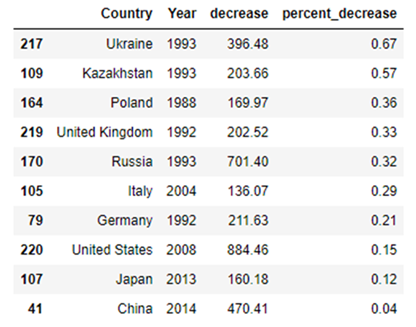
Table 5: Better table that shows largest percent decrease of largest CO2 producing Countries
This clearly showed us that Ukraine had the highest percentage drop of all the large countries. Next, we wondered what Ukraine could be doing to achieve the impressive 67% drop in CO2 emissions. We hypothesized that they most likely just stopped producing energy with coal and petroleum and switched over to nuclear or other renewable sources. To test this hypothesis, we had to plot the country’s energy type and production. This allowed us to quickly visualize the trend of all the energy types. What we found confused us.
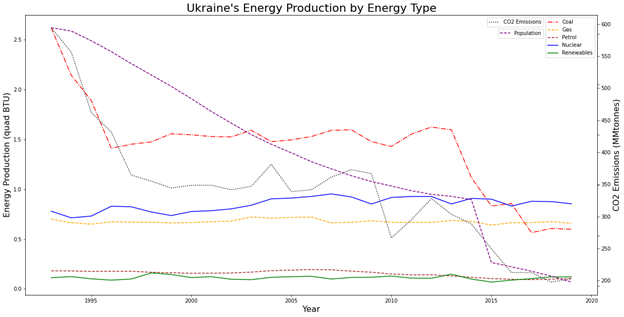
Figure 9: Shows Ukraine’s energy production by type, CO2 levels, and Population per year.
It looks like Ukraine reduced CO2 levels by reducing the amount of coal production. It's interesting that they didn't increase production in any other forms of energy to compensate for the reduced energy. This made us question what else could be going on. Why wouldn’t Ukraine increase its output to compensate for all the coal energy production loss? We decided to add in Ukraine’s population just to see what it would look like. In question 1 we found out that Japan had a declining population and there wasn’t a correlation with CO2 levels. In that case, Japan’s population had dropped very little, around 2%, and it was a recent development. Whereas in Ukraine’s case, they had a massive 20% decline in population since 1993. Although this probably isn’t the only reason for the drastic decline in CO2 levels, it is most likely a heavy contributor.
Conclusion
After cleaning and exploring the dataset, we have found multiple insights into the different factors affecting CO2 emission. To our surprise there is not a direct relationship between population growth experienced by a country and its CO2 emission levels. It does appear that more industrialized nations emit higher levels of CO2. Looking at the wealth of a nation and its emission of CO2, low-income countries emit the least amount of CO2 compared to other medium and higher income countries. Petroleum based energy has emitted the most CO2 compared to the other energy sources. There are countries that produce more energy than they consume, and the top 3 countries are Russia, Saudi Arabia, and Norway. The accumulation of the excess energy from 1980 to 2019 by the three countries is 1400 Quad BTU. This World in 1980 produced 292 Quad BTU of energy. There can be better planning for the three countries' energy production. The world has taken an initiative in reducing CO2 emissions and has increased the energy production of renewable energy. From 1980 to 2019 there has been a 300% increase in renewable energy production, and this has been a linear increase.
PostGRESQL & Python for fast Exploration and Vizualization
Introduction
This projects setting was a data engineer working with data scientists and business leaders to pull SQL queries to make better informed decisions with data. This report will review the set up of the notebook and some code is excluded for personal proprietary reasons. The goal is to show different type of basic and advance queries.
Set up
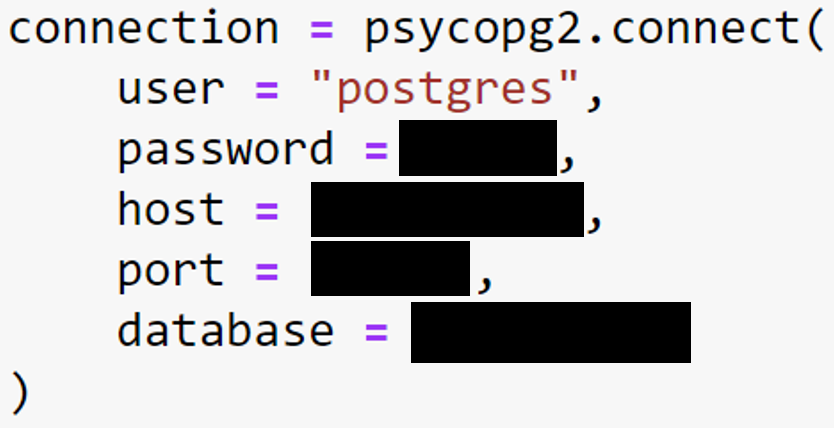
The four libraries used are math, numpy, pandas and pscopg2. The numpy and pandas package will be used to read the SQL query and put the table into a dataframe. The psycopg2 library will connect to a database via host and port number with a username and password.
ERD
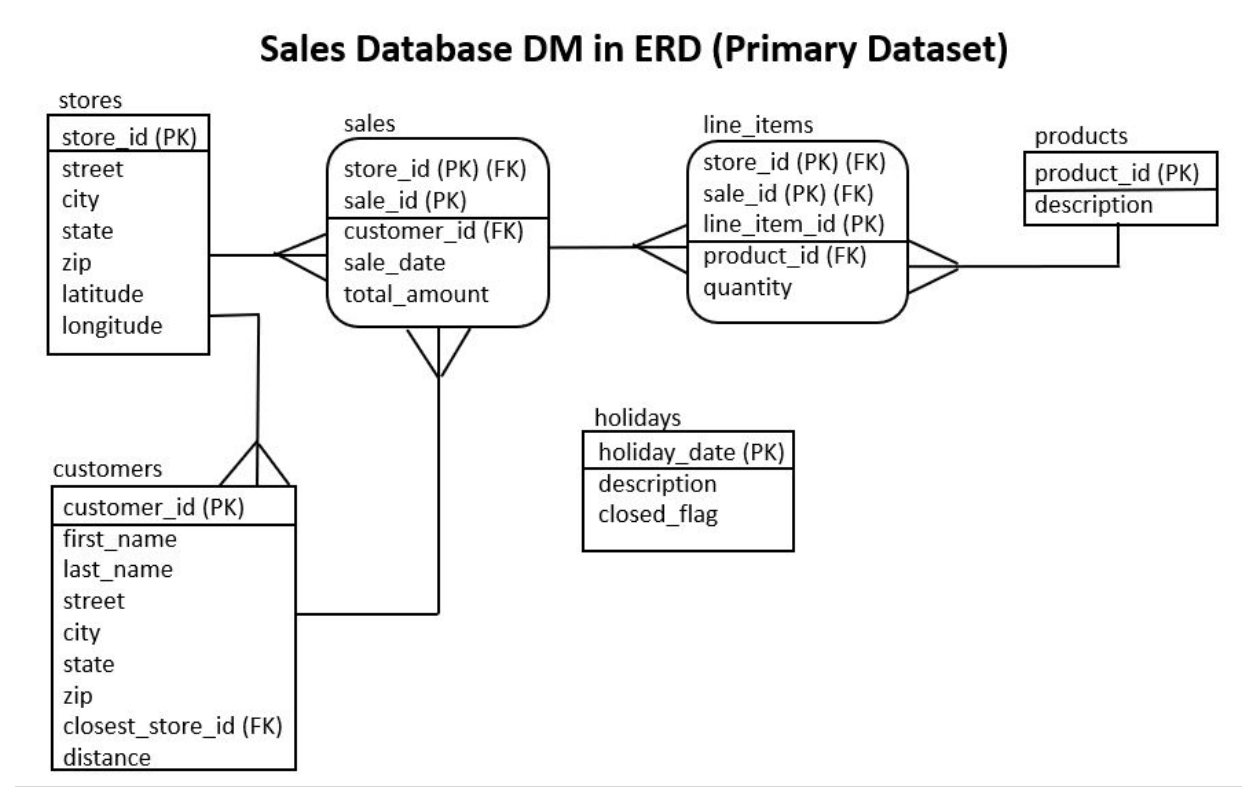
The primary goal of the Entity Relationship Diagram (ERD) is to show the tables relationship. Each box is a table with the table name written above the box. If any foreign key is part of the primary key, we use rounded corners on the box. Inside each box is a list of columns in the table. Columns that are part of the primary key are above the line and also have (PK) after them. Columns that are foreign keys have (FK) after them. When joining, join the foreign key to the primary key in the parent table. Relationships between tables are denoted using the crow's foot notation. The line touches the parent table. The crow's foot touches the child table. Dangerous joins are joins between tables not based on matching a foreign key to a primary key. They are often necessary, but be careful, as they can cause the "extra rows" problem or the "missing rows" problem. When loading data, parent rows must be loaded prior to child rows, otherwise the database will generate a foreign key violation error. When deleting data, child rows must be deleted before parent rows can be deleted, otherwise the database will generate a foreign key violation error.
Writing different queries to accomplish different business objectives
In this portion I will show different types of techniques to pull different information. The setup of each example is to discuss the business goal or obejctive, discuss key clauses or statements of each query, include a picture of each query, and the picture of each result. Clauses or statements in prior examples will not be discussed in later examples to reduce redudant information. I will note that example 10 is more of an advance example which will include all the other examples caluses and statements. I will put a focus more on the logic and structure of the code. Examples 1-9 will show how to use different sql clauses or statements to accomplish more generic requests.
Example 1
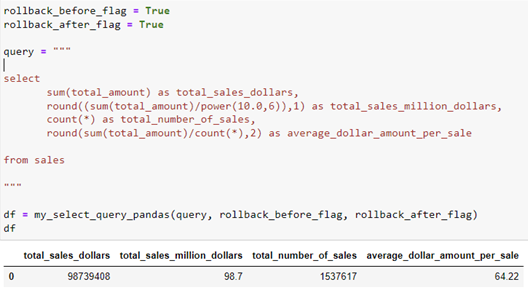
The goal in this query is to better understand the sales made by company and find the average spent per sale. In this query we used single functions to sum the total sales, count all the number of sales, and divide the total sales by the count of sales to find the average spent on a sale.
Example 2
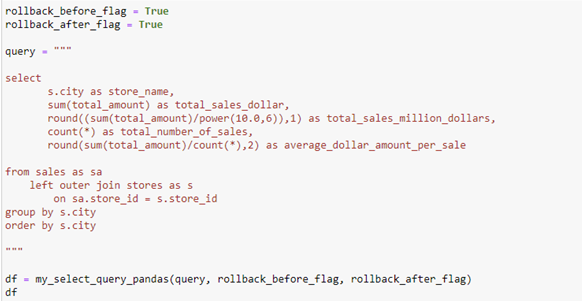
The objective for the query below is aggregate the data to different stores and take the total dollar made on sales, the count of transactions made, and the average spent on each transaction. In order to make this possible there has to be an inner or left outer join on the sales table to the store id. I chose to use an left outer join for to show order importance since an inner join’s order does not matter. The join is on a the store_id which is the primary key for both the sales and stores table (please refer to the ERD above). To aggregate the stores to apply different numerical manipulation you will need to apply the group function. At the end I apply and order by function to sort the data in ascending order by stores city name.
Example 3
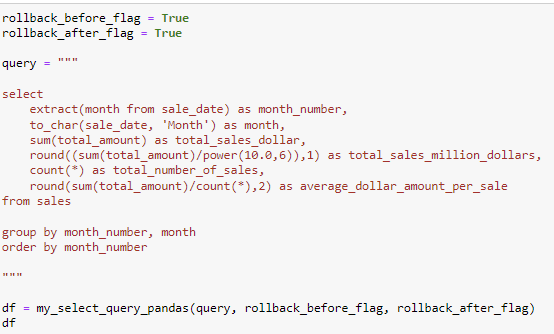
The goal of the query below is to query the same information as example 1 and 2 but instead aggregating by the month. In order to accomplish this query, you will need to first extract the month number from the sale_date which is scalar subquery. After extracting the month number, you can use the to_char function to tie each month number to its represented month. By grouping by the month number and month you can aggregate the data into each month and apply different mathematical functions.
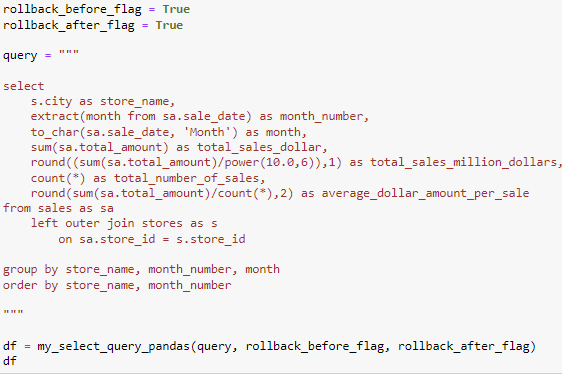
Example 4
The goal for this query is to view sales data for each store at different months. In this example we add another complexity by combining what we accomplished in example 2 and 3. By extracting the month number from the sales table, doing an inner join with the sales and stores table on the store _id, and grouping by the object variables then can you accomplish the examples goal. Please refer to example 2 and 3 for a more depth look at the join and grouping.
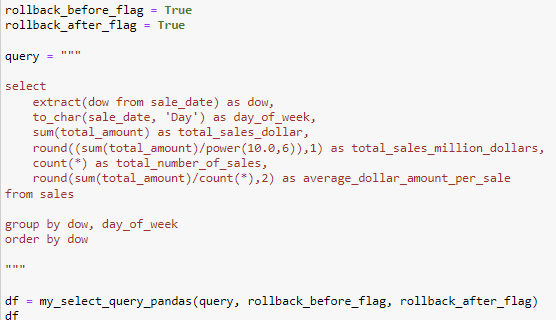
Example 5
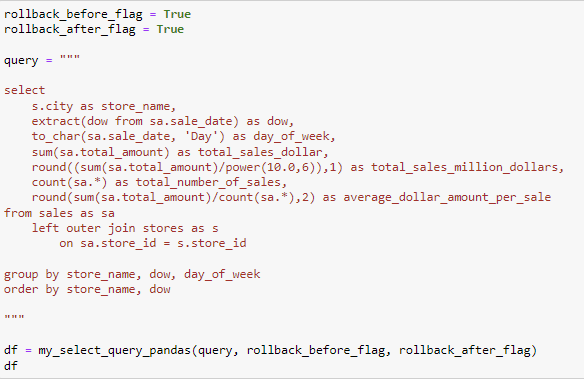
The goal for this query is the same as example 3, however you want to know the sales by week. The code is very similar to example 4 and so my explanation for this example will be more focused on the difference. In example 5 the extract function is taking the day of week from the sale_date record for that specific row. The days name will be identified by using the to_char function.
Example 6
The objective for the query is to aggregate the data by store name and day of the week in order to perform some mathematical functions. This example is a combination of example 4 and 5. The key difference between this example and 5 performing a join function between the stores and sales table on the primary key, store_id. By adding a new character column you will need to include that in the grouping function.
Example 7
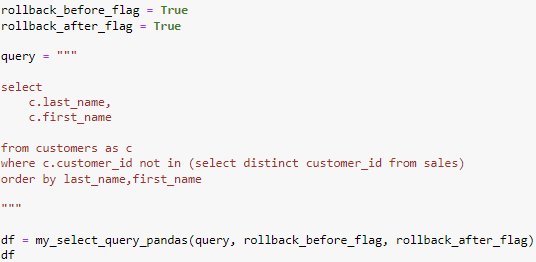
The goal of this example is to find the customers who have signed up for the stores subscription, however have not purchased any goods. Here we have a query to select the last and first name of the customer from the customer table. We want to filter out the customers who haven’t purchased anything by using a where clause and a scalar subquery. By using the customer_id from customers table that are not in the sales table we can accomplish the goal.
Example 8
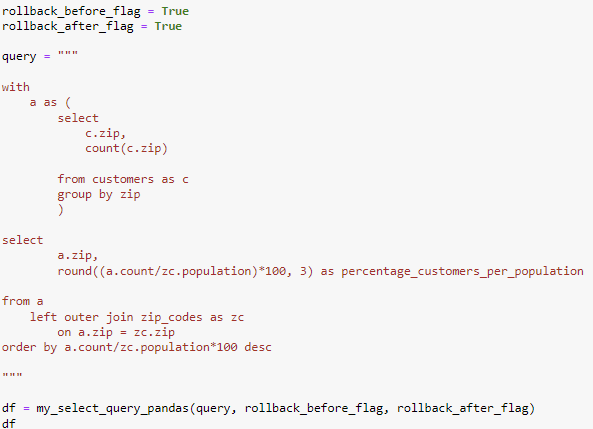
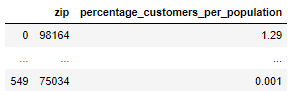
The goal of the query is to better understand the demographics of the customer by analyzing the percentage of customers in varying areas (zip codes). In order to accomplish this goad we will have to do a subquery with a with clause. We start by choosing our columns by selecting the zip code and the customer population percentage of each column. The customer population percentage is the total count of customers we have divided by the total population in the zip code from another table. I chose to use the zip code table as my main table and did a dangerous join with the customer table on the zip variable. The zip variable is a unique identifier and is a valid justification for the dangerous join (non-primary and foreign key joins). I used the with clause to count the number of customers we have in each zip code from the customers’ table.
Example 9
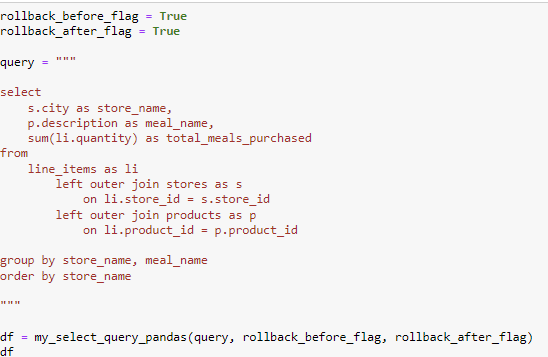
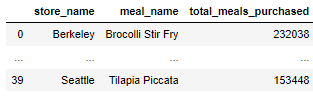
The goal of the objective is to see how many meals were purchased by store and by meal. In order to accomplish this goal, we need to do multiple joins with multiple tables. I utilized the table that contained the information I wanted in order to do join with other tables to accumulate more details on each data point. I used the line_items table to join the stores table on the store_id to get information on the store and the product table on the product_id to gather the description on each product.
Example 10
For this example, I will put an emphasis on the logic of the code and how it was put together rather than explain the different SQL clauses and statements used. The goal of this example is to find the holiday days (including 7 days prior and after that holiday) where the actual sales differ by more than 15% from their expected sale for that day of the week.
In order to accommodate this request by using one query, you will have to rely on several subqueries along with the main query. This is done by using the with clause and 5 subqueries within the main query. Taking this modular approach helps with aggregating different groups and then combining the data into a single desired data frame. The first subquery needed is creating a holidays table from the internal SQL table called holiday and, in my code, denoted as e. This subquery will be the foundation for identifying all the holiday data for that year. The second subquery needed is creating all the days of the year and this can be done using the generate series table. This query will assist the connection to the holidays date and the date within that calendar year.
The third subquery created will identify all general days of the week in a year and group them for that specific day of the week. This can be done using the generate series table (an internal SQL function) and the group by function. This subquery is within the with clause, and in my code is denoted as c. The importance of this function is to find the number of Monday, Tuesday, etc within a year. This table will be used as the denominator to find the actual sales dollars and expected sales dollars.
The fourth subquery will be the total sales made for each day by aggregating the sums for each specific day of the week and denoted as a. The coalesce function is introduced to handle the nans. Doing an EDA prior to this study, I found that the nans are days the store is closed like Christmas day. The fifth subquery needed is finding the expected sales of each general day of the week. This is done by aggregating the sum of the sales for each general day of the week. For example, each general day of the week could be Monday, Tuesday, etc and there will be 7 total rows for this table.
Finally, were close to the finish line and we need to combine all the subqueries to make the table we desire. We first want to use our date analyzed table as the main table in the query and this is because this will list all the days of the year. We will have four join clauses for each of the subqueries and use table d as the frame of reference.
The first subquery is joining the day of the week (table c) for each day of the year (table d) on the day of the year key. Next, we will join the each day of the year table (table d) with the actual sales (table a) of that day on the sale date key. We will join the each day of the year table (table d) with the expected sales for that day table (table b) on the day of the week key. The next join will be a tricky join where you do a join with the holidays table (table e) with each day of the year table (table d). The join uses a between clause with a numerical function to include the 7 days before the holiday date and 7 days after the holiday date using the date of the year key. This will connect the holiday with the days of the holiday week. Now we can apply some mathematical function to get the actual sales data, expected sales data, and ratio of the actual and expected. This is done by grouping the holiday name, data analyzed, and day of the week. The actual sales dollars are the total sales made that day divided by the count of the general day of the week. The expected sales are the total sales for the general day of the week by the count of the general day of the week. The ratio is the actual sales dollars divided by expected sales dollar. The last thing to do is filter the dates to see where the store underperformed in sales by more than 15%. By using the where clause and setting the ratio of the actual and expected to be less than 85% you can code this desired table.
Analysis and Data Visualization
The query shown in example 4 and shown below is used to create quick data visualization. The goal of this section is to show that you can pull a quick query and analyze data very fast with python and the pyscopg2 package. The plots below were created using the seaborn and matplotlib libraries. The set up for each example is to show the picture of the python code to create the plots, the plots, and my personal thoughts.
Example 1
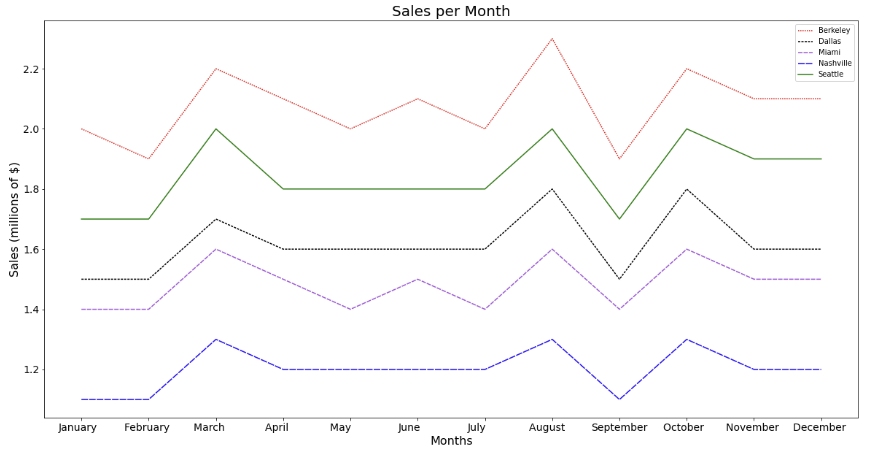
The plot was created using the matplotlib library and shows the sales of millions of dollars for all the varying stores each month. It appears that Berkeley makes the most sales while Nashville struggles to make equivalent sales. In March, August, and October there seems to be a boom in sales while the months between March and August there seems to be a slow period of sales. This can help prepare the stores to stock more up on the peak season and to wean down the stock in between the peak seasons.
Example 2
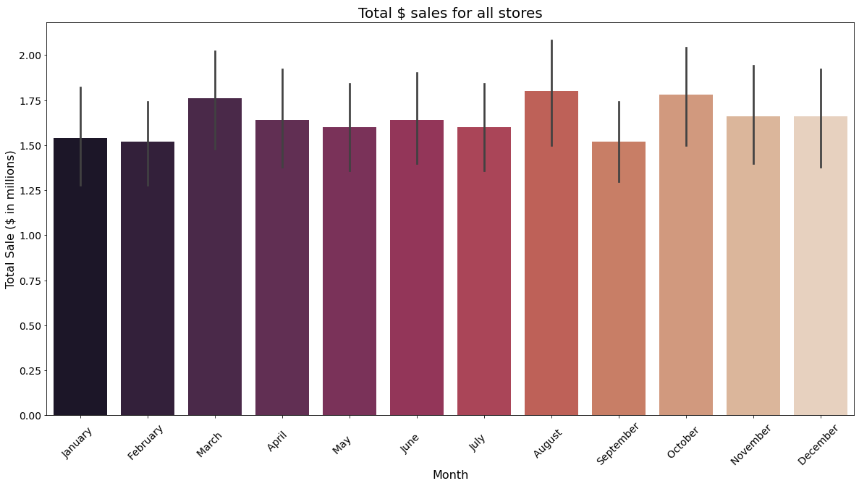
The plot shown in example 2 was created using the seaborn library and represents all the sales stores by varying month. The left axis represents total sales in millions of dollars and you can see the same trend as example 1 where March, August, and October had the peak sales. Since example 2 stores followed the same trend the same information can be derived from example 1. The goal of this example is to show the use of a seaborn plot and the ease of use.
Conclusion
Running quick queries and data exploration can be done with the combination of python and psycopg2. By importing the pyscopg2 library and creating a connection with the SQL database allows the coder to work effectively and quickly. Using this method can also be useful in building data pipelines and validating that the data your pulling is being captured and correctly formatted.
Data Wrangling
By: Christian Lee
Introduction
The project setting was a data engineering group receiving third party vendor data that is essential for analytics. The goal is to review the data in postgres, perform data validation, staging the new formatted data tables, importing CSV/Nested JSON files, and exporting data tables to CSV/Excel for business stakeholders. The data received is a JSON file and will be parsed and staged into postgres.
Setup
The four libraries used are math, numpy, pandas and pscopg2. The numpy and pandas package will be used to read the SQL query and put the table into a dataframe. The psycopg2 library will connect to a database via host and port number with a username and password. The csv and JSON library will be used to assist in parsing the data.
CSV to Postgres Database
In this scenario, the vendor is providing clean data in a CSV format. We will approach this scenario with creating a table, with different data columns for each csv file. The csv file has one sheet and is easily imported into postgres.
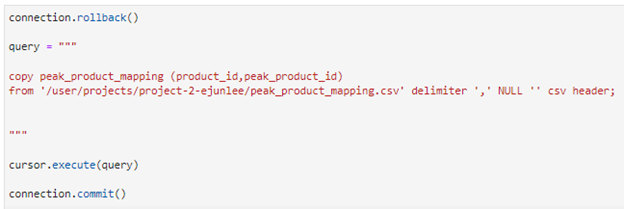
In this example I first looked at the CSV to see the different data columns for the respective file. After doing a little investigation, I created a peak product mapping table with a product_id, peak product id, and a primary key column. The reason for this being a peak product mapping table is first seeing the data in SQL and if everything checks out, we will then transfer the data in our data warehouse.
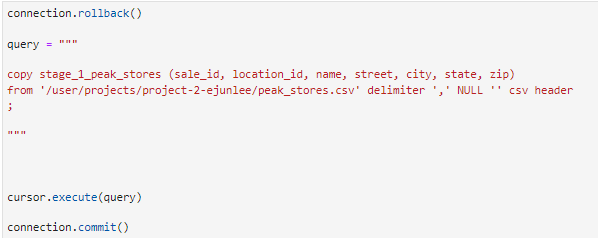
Here we copy the data from the csv to our newly created table. We execute our cursor to make sure the transaction has occurred within our database.
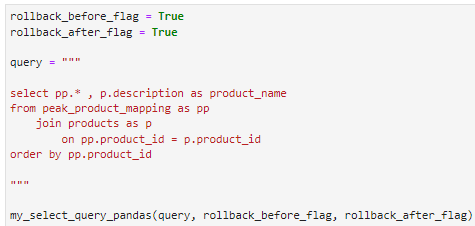
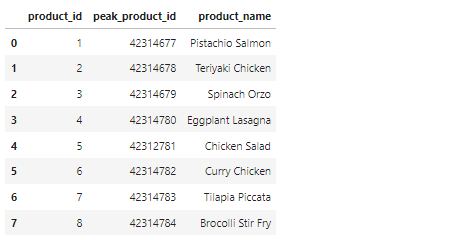
After importing the data, I check to see if the data was imported correctly by running a simple SQL query.
Vendor Provides a nested JSON File Scenario
In this business case, I parse and select data from the nested JSON file and export the data to CSV. The rationale for doing this data transformation is to easily import the data into the postgres database. A flat JSON file would be easy to import into a postgres database, however a nested JSON file would need to be modified.
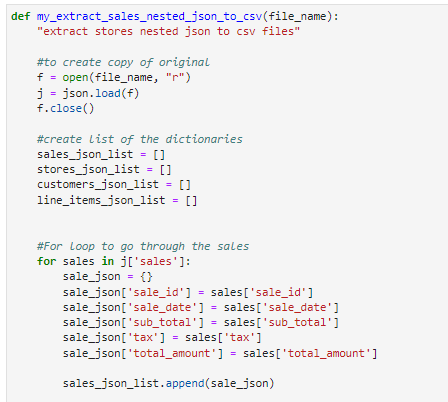
We first want to develop a custom function to deal with the vendors JSON file. I first went through the vendors data framework and learned the setup to build the structure for the code. I first want to create an object of the JSON file to work with. I then create a list to store the dictionaries that are being pulled from the JSON file. The individual records will be dictionaries inserted to a final list which will be exported into a csv file. After creating each tables list, we run a for loop to go through each sale. The vendors data frame is first each sale, and within each data record there are information on the stores and customer list. Within each sales record are records on the quantity and type of good sold.
Above is the code to create a csv file for each data table, write data within each file, and saving the CSV file.
The above code is to call the function for that particular JSON file. If the vendor JSON file is consistently the same, then the code is valid. However, if the vendor provides another JSON framework, the code will need to be modified to extract data.
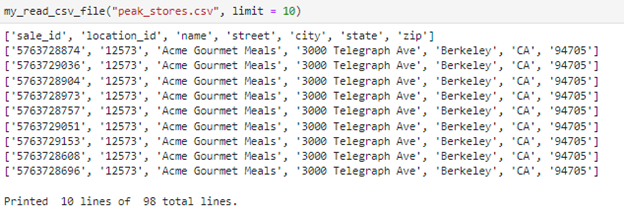
Above is the picture of the results to ensure the file has been created in the right format for postgres importation and this is one way to do a quality check.
Create, Load, and Validate Staging Tables
Now that we have the files prepped and ready to be imported into the database, we will need to create the staging tables.
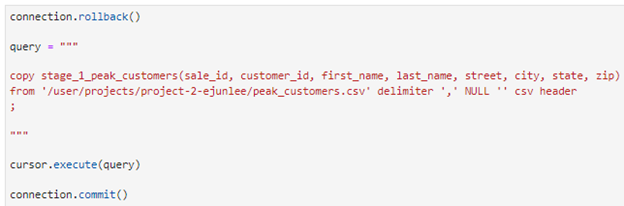
Here we create the tables with a stage_id in order to track the records. I assign a varchar to each data type in case there are any issues with the data, and if the data type is incorrect then importing the data will generate errors. Then we will import the csv files into the database. I will go through the process of data validation before creating official tables.
Here we verify the tables were loaded correctly.
The goal of the query above is to check if the numeric data columns are numeric and id the sale_date columns are formatted correctly. If the data cannot be transformed to numeric, the query would indicate an error.
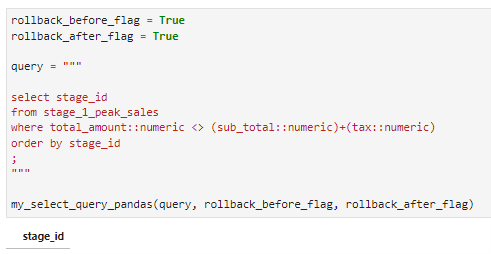
Here we run a query to validate the math on the sub_total, tax, and total_amount in the staged 1 peak sales table. The query returns an empty data frame, which tells us that the data does not have any conflicting issues with the total cost.
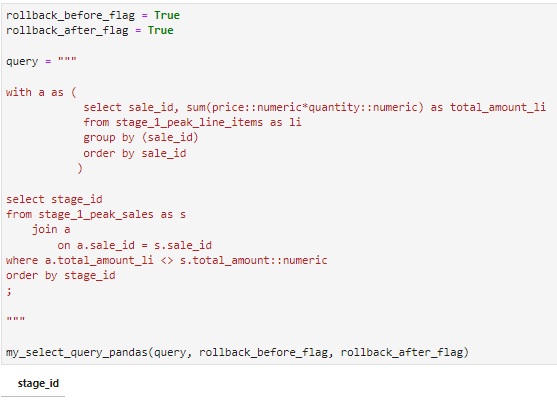
The query above is to validate the math between the two different tables. The query uses a with statement to make the comparison possible and in order to do numerical comparison we had to change the data type to numeric. In this case the two data tables have consistency with the total amount charged for each sale.
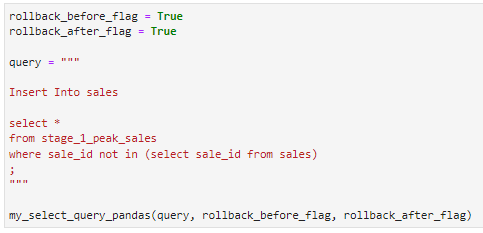
Here we insert the records from the stage_1_peak_sales into the sales table. We include a where clause to not take any records that are already in the sales table.
The query above is to remove the stage_1_peak_sales to maintain good data practices and remove any unneeded data.
Democrats or Republicans. Who had more difficulty voting?
1. Importance and Context
Voter engagement for the 2020 United States presidential election was at record levels, with more voters saying “it really matters” who wins the presidency than at any point over the last twenty years. At the same time, challenges such as the pandemic and social unrest led to half of the registered voters indicating it would be difficult to vote in the election. There has been a significant change since October 2018, shortly before that year’s midterm election, when 85% of registered voters said it would be easy to vote in the midterm elections. A better understanding of the various influencers of voter turnout is useful for your organization for party strategists and campaign managers.
This study will focus on the 2020 election and better understand the difficulty levels in voting between parties, which is one of many factors impacting voter turnout. Specifically, the goal of the analysis is to address the following research question:
Did Democratic voters or Republican voters experience more difficulty voting in the 2020 election?
As consultants we are here to answer this question in order to provide guidance and a foundation for your future research. This includes determining if voter difficulty is a major bellwether of turnout and, if so, further decomposing the factors that lead to these difficulty levels, such as registration, absentee versus in-person voting, long waits at polling places, or bad weather, which can be analyzed in the future. In addition, this analysis will allow us to identify if the difference in difficulty voting between Republicans vs. Democrats was statistically significant in the recent election. If the results are statistically significant, the reasons for difficulty in voting can be further assessed and mitigated.
2. Data and Methodology
The study utilized data from the 2020 Times Series Study conducted by the American National Election Studies (ANES). The Times Series Study interviewed 8280 individuals and comprised pre-election and post-election interviews from August 2020 through the end of December 2020. The sample we created from a subset of the ANES Times Series Study is limited in terms of generalizing to the US voter population across all demographic groups. This is due to the fact that we didn't leverage the weighting provided by ANES that is based on the US census.
Before answering the question of which political party had more difficulty voting, we need to operationalize the concepts, including who is a voter, their political affiliation, and the type of difficulty the individual had. Having this information provides context to exhibit who had more difficulty voting statistically.
To classify a respondent as a voter, we look at those who have already registered to vote (at their current address, another address, or without an address) or are planning on registering to vote. As registering is a prerequisite for voting, we believe this variable is a strong indicator of being a voter. For V201008, values 1, 2, and 3 gave information about their registration address, while the other values did not give additional information. V201009 determined if voters were registered to vote, and value 1 gave applicable information for the study.
We use the following fields for voter identification:
Variable_Name
Description
Value
V201008
PRE: WHERE IS R REGISTERED TO VOTE (PRE-ELECTION)
1,2,3
V201009
PRE: WEB ONLY: IS R WITHOUT ADDRESS REGISTERED TO VOTE (PRE-ELECTION)
1
There are multiple ways to identify a respondent's respective party, for instance, voting behavior in past elections, voting in the primaries, the party they are currently registered to, etc. The pre-election self-identified affiliation variable was the best way to measure a respondent's political stance due to the quality and quantity of the data. Their political stance before and during the act of voting was taken into consideration. Values 1 and 2 correspond to the political party, while the other values did not give any more information.
We use the following field for party affiliation:
Variable_Name
Description
Value
V201228
PRE: PARTY ID: DOES R THINK OF SELF AS DEMOCRAT, REPUBLICAN, OR INDEPENDENT
1,2
How difficult it was for respondents to vote and the main reason respondents did not vote were used to determine the difficulty in voting. The combination of the two factors encompassed how hard it was for voters to cast their vote and why they found voting difficult. The values (2,3,4,5) of having difficulty voting were used in the study to determine which party had more difficulty for V202119. We utilized values that were not in the respondents control that induced difficulty in voting for V202123.
We use the following field for party affiliation:
Variable_Name
Description
Value
V202119
POST: HOW DIFFICULT WAS IT FOR R TO VOTE
2, 3, 4, 5
V202123
POST: MAIN REASON R DID NOT VOTE
9, 10, 11, 12, 13, 14, 15
After assigning true or false values based on if it was difficult for party members to vote, we observed how many democrats and republicans had difficulty voting.
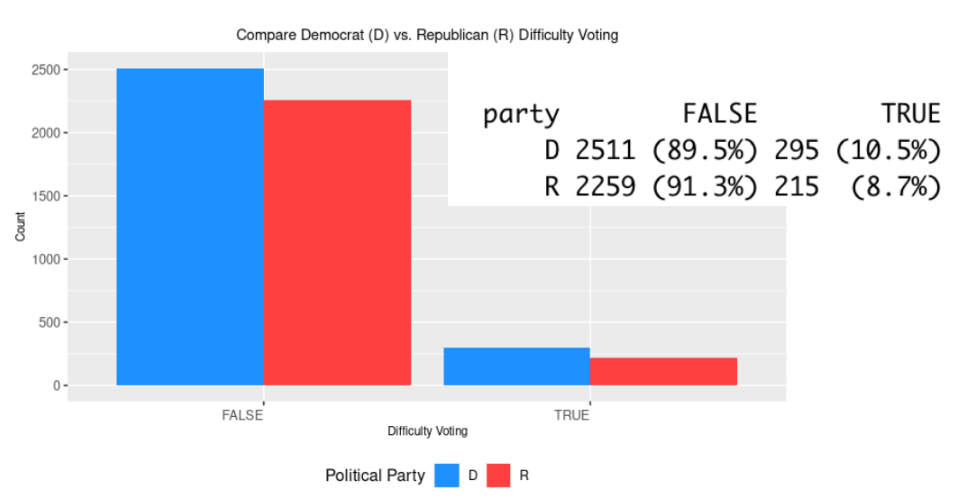
Difficulty Voting Democrats(D) vs Republicans(R)
Democrats had more true and false values, which aligned with the population of democrats being higher than republicans. However, we looked into the true and false cases as a percentage of the respective party population samples. The percentage difference between true and false was not notable between parties. Utilizing the party as a grouping variable and defining the response variable as proportional count of difficulties per group we can conduct some statistical tests.
We evaluated various reputable hypothesis tests to determine which is best for answering our research question. After reviewing the assumptions that must be met for each test, we were able to narrow our choices down to the two-sample proportion test and the comparison version of the Wilcoxon rank sum test. As we evaluated difficulty as a binary true or false value instead of a scale of ordered categories, the data was determined to be more appropriately wrangled for the proportion test. Additionally, the Wilcoxon rank sum test is of lesser statistical power; therefore, we determined the proportion test was best suited for our analysis from these two test options.
The proportional statistic assumptions were validated for proper use of the test statistic. The first assumption for the proportional two-group comparison test was independence and identical distributions (i.i.d). Independence can be assumed since random sampling occurred, and one sample's information cannot be inferred from other samples. However, the population of the samples changes from 8280 (pre-election interviews) to 7,782 (post-election interviews). There is a 7% decrease in the population size, which will not heavily affect the probability distribution. The following other assumptions are correct as the sample population follows a binomial distribution, and the data are simple random values from the population.
While evaluating for practical significance, Cohen’s d is not well suited as it requires normality. For our binary data, we chose the Phi coefficient, which yielded a value of -0.031. The result indicates that there is virtually no relationship between political party and voter difficulty, meaning other factors drive difficulty.
Below is the accounting table summarizing the data wrangling after the exploratory data analysis (EDA) of the dataset.
Cause
Number of Samples Available for Analysis (after removal for cause)
Removed Number Samples for cause
Start
8280
0
Non-Voter
7888
392
Independents (non-partisans) or no party affiliation provided
5280
2608
Note: For the response variable value that is not included in the selections, we assign a binary/boolean value to the record. Therefore, we do not have any missing or out-of-range response variable values.
3. Result
As we have two independent samples, Democratic voters and Republican voters, and difficulty being defined and organized as binary/boolean values, we derived the counts for total voters and the counts for voters with difficulty for each party. We use the proportion hypothesis test for binary data.
Null Hypothesis: The proportion of Democrat voters with difficulty voting is equal to the proportion of Republican voters with difficulty voting.
H0: p1=p2, versus select one HA: p1≠p2
The proportion hypothesis test returns a p-value of 0.02847, which leads us to fail to reject the null hypothesis as it is not within the rejection region (< 0.025).The result is not statistically significant.
4. Discussion
While this is limited based on how Democrats and Republicans responded to ANES interviews, our study found evidence that voting difficulty does not have a strong relationship with the voter's political party. It is consistent with our findings that there is no significant difference in the Democrat and Republican populations we compared for voting difficulty. Additionally, we have shown that difficulty wasn’t experienced at a very high rate across either party, with just over 10% of Democrats and Republicans expressing this in their survey responses.
Since the 2020 election had the highest turnout in United States history, it does not appear that difficulty had a significant role in preventing people from getting to the polls. Instead, it may make sense for future research to look at other predictors of voter turnout, such as education or socioeconomic status.
Estimating the Impact of Synthetic Diamond’s Weight on Sale Price
1. Introduction
New technological advances in synthetic diamond manufacturing have led to increased carats of the produced
synthetic diamonds. Acme Synthetic Diamond Company is still using the older manufacturing process. Since
upgrading the new equipment will be expensive, they have to decide if it is economically viable. Generally,
diamonds with larger weights or carat values sell for higher prices, a more precise data analysis is required
to justify such a large investment.
This study estimates how large of a factor the carats of synthetic diamonds are on the sale price of the
diamond. We leverage synthetic diamond sales observations with the sold diamonds’ characteristics, including
carat, color, clarity, cut, length, width, and depth. Applying a set of regression models, we estimate how
much the synthetic diamond weight in carats influences price with respect to other factors.
2. Data and Methodology
The data in this study comes from the diamonds dataset on Kaggle.
It was made publicly available by Abhijit Singh in 2021.The data includes 53,940 observations of synthetic diamond sales with 10 variables.
We transformed 7 of the 10 variables to the log scale to remove skewness and make them more symmetrical
with more normal distributions. We have determined that records with a value of zero in columns volume,
length, width, depth, and table were to be removed since it is impossible for a physical dimension of a diamond
to be an absolute zero. This filtering removes 20 observations and leaves us with 53,920 observations. In
addition, we removed 17 observations that have the infinite natural log volume value and that leaves us with
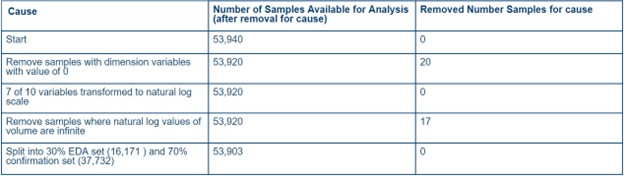
53,903 observationsin our data set
We assigned 30% of the data to the exploration set, 16,171 observations, and the remaining 70% of the
data to the confirmation set, which is 37,732 observations. The large observation sizes are sufficient for the
central limit theorem (CLT) to hold. The exploration set was used to inspect the data’s trend and build
models, while the confirmation set was used to test our model on new data.
Table 1: Accounting Table
To predict the price model with the different diamond features, we had to operationalize varying features. The
price is metric and was operationalized as the response variable of the model, while the carat, volume, clarity,
and color were used as predictor variables. The volume variable, a metric feature, is made of three different
features in the data set, the multiplication of the width_in_mm, height_in_mm, and depth_in_mm of the
diamond. The rationale for multiplying the three metric features to be one feature denoted as volume is
to simplify the interpretation of the model. The clarity, color, and cut are categorical variables that were
operationalized by being hot encoded to ordinal features. Having these variables as ordinals defines the
categorical variables to their price worth based on their physical properties and will generate a more precise
model.
Utilizing the exploration set and going through the EDA process, plotting the different variables against
price, generating different histograms, and running some models with the exploration set, we determined
a natural log of of skewed variables depth_in_percent, depth_in_mm, carat, price, width_in_mm,
length_in_mm, table_in_percent would produce a better model.
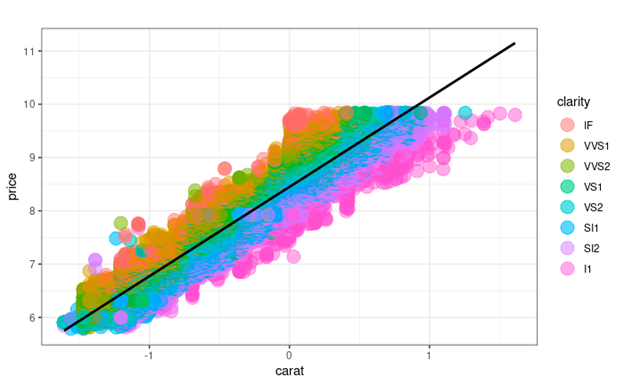
Figure 1: Synthetic Diamond Price Based on Carat and Clarity
We are interested in estimating the sale price of synthetic diamonds based on the weight of the diamonds in
carats. β0 is the intercept, and β1 is the expected change in price based on per unit change in C (carats). Z
is a row vector of additional covariates and γ is a column vector of coefficients.
3. Results
The stargazer table shows the results of the three log-log regressions, and model 1 is our baseline model.
Across all linear models, the key coefficient was carats and was highly and statistically significant. It
is a positive coefficient with point estimates ranging from 1.68 to 1.87. Model 2 has the highest positive
coefficient for carats of 1.87, while models 1 and 3 also have the positive coefficient for carats of 1.68 and 1.27
respectively. We notice in model 3, volume is highly correlated with carat and takes away some explainability
of carat, so we decided model 2 is best suited for our estimations. Applying model 2 with the point estimates
of 1.87, we interpreted the result that a 10% increase in carats results in a 19.51% increase in price, and a
20% increase in carats is a 40.63% increase in price. As a result, the new equipment with the new process
that increases the carats has both practical and statistical significance to the synthetic diamond sales price.
In model 2, we include the independent variables of color and clarity in the linear models. We want to
find out if these two variables have any effect on the industrial diamond price. The regression table resultsshow that both variables are highly and statistically significant and have a negative coefficient. Therefore,
it confirms that they do affect the industrial diamond price.
The main difference between models 2 and 3 is the additional independent variable of volume. In model
3, we added an interaction term of volume, which is the product of industrial diamond length, width, and
depth.The regression table shows that it is also statistically significant.
Table 2: Stargazer Table
4. Limitations
The model has over fifty-seven thousand data points which satisfy the large sample assumption model
and allows us to apply a less stringent OLS regression with fewer assumptions. The first assumption is
independence and identically distributed (IID) Data. The data could be assumed independent since the
data was collected randomly; however, the geographic sampling location of the data is unknown. This could
lead to the clustering of information on diamond prices, and the geographic location of buying a diamond
could vary the price. The data is identically distributed since we did not remove a significant amount of
data (less than 0.04% of data) before or after creating the model and the data points come from the same
probability distribution. Please refer to the brief description section for data removal before modeling.
The other aspect to investigate is the variance of the tails. We plotted the histograms of the metric variables
(model, price, carat, and volume) and noticed non-normal distributions. The distributions seen were bimodal
and skewed, which could lead to a bias in the model’s estimate. There seems to be some conflict with the
large sample assumption of a unique best linear predictor (BLP), given the distribution of price on carat
does display heavy tails. This does not mean the predictor is inaccurate in predicting price; however, we can
not assume there is a unique BLP.
Omitted variables do not interact with the key variable in the true model in the classic omitted variables
framework. There may be unknown variables that may bias our estimates that could bias our estimate
positively or negatively. For example, the labor costs leading to the sale of diamonds could be higher in certain economic conditions, driving up the cost of goods sold and, ultimately, the diamond price. There are
such variables that we cannot account for, but it could contribute to our omitted variable bias.
5. Conclusion
In our models, carat is the most important feature in determining the price of a synthetic diamond with
the largest coefficient in the regression tables. However, the regression tables also showed there are other
predictors of note in volume, clarity and color, potentially adding bias to our estimates that showed 10% and
20% increases in carats leads to 19.51% and 40.63% increases of sale price respectively. That said, with 0.98
for R-squared we have enough confidence to recommend that Acme Synthetic Diamond Company should
upgrade to the new equipment. We estimate the larger diamonds produced in carats will bring in more sales
revenue, allowing them to pay off the new equipment investment in about three years.
In future research, we may want to collect additional data to estimate the diamond price further. Possible
new variables include seasonality, Gemological Institute of America (GIA) certification, the energy used in
the manufacturing process, the diamond shape, the jewelry type, or other factors. We hope our research can
help Acme Synthetic Diamond Company produce beautiful and profitable industrial diamonds for generations
of customers to come.
Currently In Progress
Sales Review Dashboard
Goal of the Dashboard:
Is creating an interactive and influential dashboard that displays company latest sales data that can be viewed by the regional leads and peers.
The assumption is that viewers have used tableau before.
The dashboard will be composed of:
• Total sales
• Sales per region
• Sales per year
• Sales, # of sales, # of customers for each region
• Top selling categories per region
• A section of the order details for each region for a deeper dive
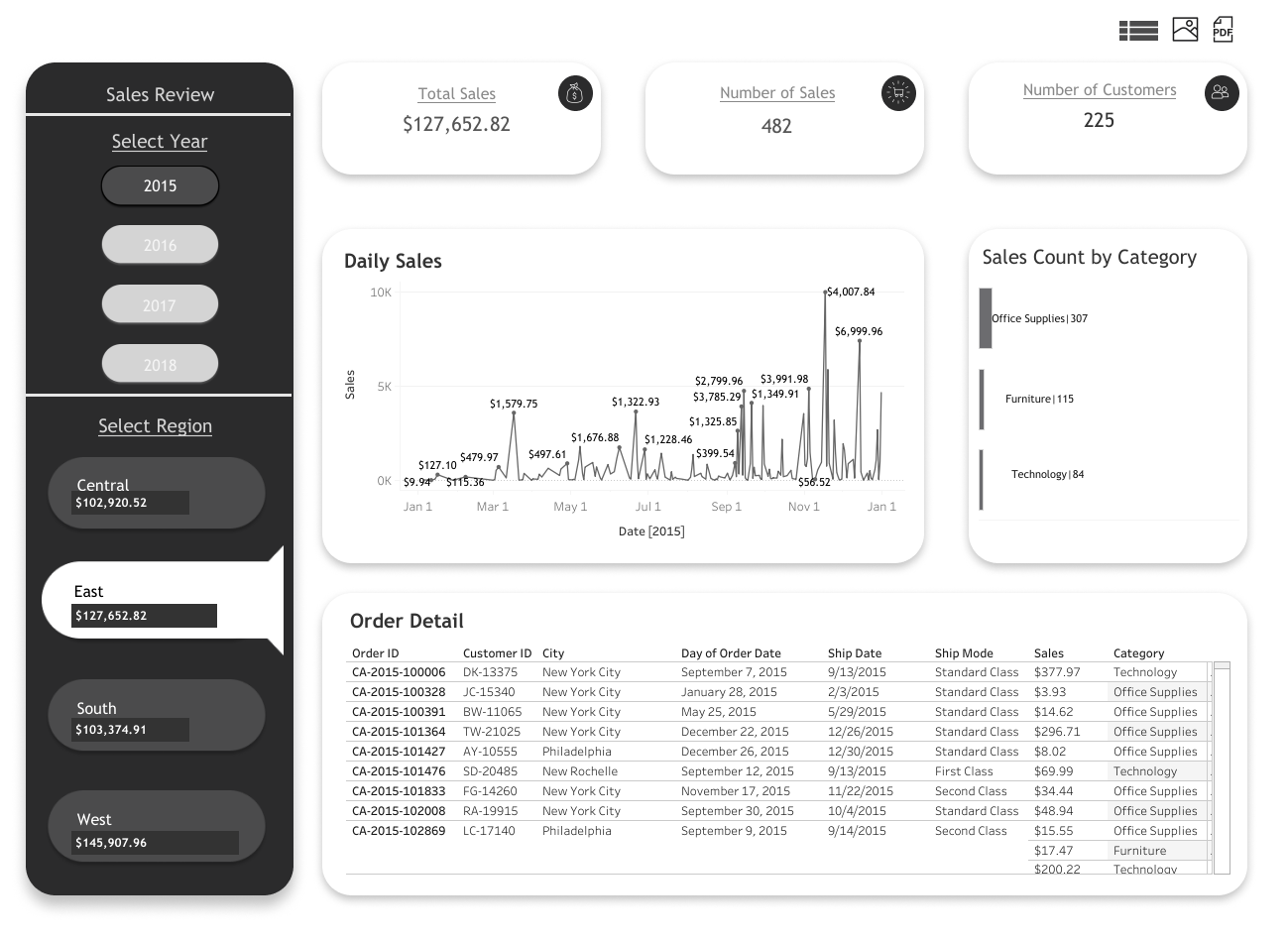
Below is an image of the main dashboard. You are able to filter the year and region by clicking the button on the left panel. The banners, line plot, horizontal bar chart, and the order details will be updated by the filter buttons on the left panel.
There are three buttons above the number of curstomers banner. From left to right, The grid button will expand the order details for a better view, the image button will download the dashboard as a picture, and the pdf button will download the file as a pdf.
The picture below is the expanded view of the order details. To go back to the main dashboard you will need to reclick the grid button on the upper right corner.
Figma was used to create the template and the icons ar from noun projects.
Click the button below to see the dashboard
Dashboard Guidelines
My thoughts and personal belief to build dashboards can be found in the button below.
My personal belief in developing Visual Boards
When building this dashboard, I used 5 key principles to design the look and feel of the dashboard.
1.) Gathering the Requirements
When building a dashboard its good to start off by understanding and stating the goal of the project/dashboard. Next is knowing who will be using the dashboard and design the interaction with the person analytical maturity. Through out the process you should be trying to have touch points with the users to curate the dashboard even further.
Throughout the development you will consistently refine and reprioritize the business questions, discover and document insights, and determine the different plots and figures needed to effectively answer the question.
2.) Create a Template
When creating a template use figures and plots that are relevant and do not leave room for fluff. Use blank text and boxes to figure the placement and design to your grid. Use varying size and positions to create hierarchy and look at the color scheme last.
3.) Use Icons and Art to your Advantage
Want to use icons that not distracting, communicate its meaning and easy to recognize. Make sure the icons follow with the format and style of the dashboard, and this can be achieved with using the same color scheme. If the icons cannot fully descript an section, use concise labels to provide context.
4.) Choose Colors that Matter
5.) Be Specific with your Fonts
Stick to on legible font and no more than 4 different font sizes on the board. Be strategic with fonts colors, bolding, and use alignment correctly (Not everything has to be center aligned).
Elements
Text
This is bold and this is strong. This is italic and this is emphasized.
This is superscript text and this is subscript text.
This is underlined and this is code: for (;;) { ... }. Finally, this is a link.
Heading Level 2
Heading Level 3
Heading Level 4
Heading Level 5
Heading Level 6
i = 0;
while (!deck.isInOrder()) {
print 'Iteration ' + i;
deck.shuffle();
i++;
}
print 'It took ' + i + ' iterations to sort the deck.';